The Evolution of Music and AI Technology
Dillon Ranwala, July 23, 2020
Emergent technologies have shaped the world of music since its conception. From the advent of recordings, to an electronic revolution of music, and now to AI technology, you can see how the role of technology in the artistic process is continually growing. Right now, many current breakthroughs that are pushing boundaries in the music world have been spurred by decades of research and discovery in AI technology. In this post, we will track the evolution of AI music methods to see how this technology can create new sounds, write melodies, develop entire compositions, and even recreate human singing.

Image by Menno van Dijk
In particular, the role of artificial intelligence in both
understanding and creating music has significantly grown since the
1950s. From rudimentary algorithms to a multi-faceted industry with
intelligent-music systems, the progressive growth in AI music
intelligence displays a technical expansion of AI methodologies.
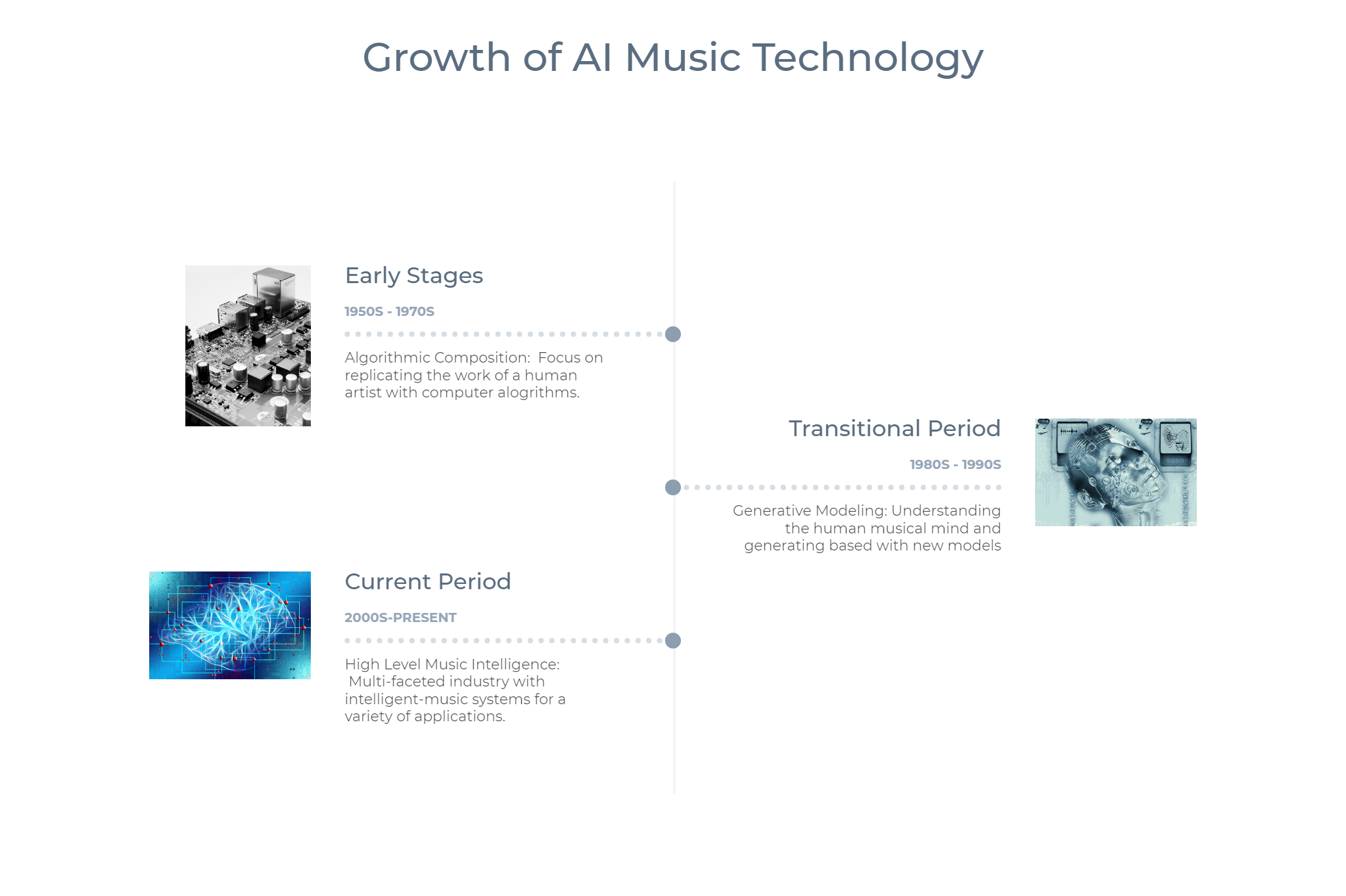
Timeline of the 3 Major Phases of Music AI Growth
Early Stages (1950s - 1970s)
The first attempts at computer-generated music appeared in the 1950s with a focus on algorithmic music creation. The advent of computer-generated music by pioneers like Alan Turing with the Manchester Mark II computer opened up multiple possibilities for research into music intelligence where computational systems could recognize, create, and analyze music.

Turing helped create one of the first recordings of computer music by repurposing signal sounds in one of the early Manchester computers. Photo from The Science & Society Picture Library.
Specifically, early experiments focused on algorithmic
composition (a computer using formal sets of rules to create music). In
1957, we see the first work composed solely by artificial intelligence —
Illiac Suite for String Quartet.

Lejaren Hiller and Leonard Isaacson. Photo from Illinois Distributed Museum
Through the use of mathematical models and algorithms,
Lejaren Hiller (an American composer) and Leonard Isaacson (an American
composer and mathematician) made Illiac Suite, the first original piece
composed by a computer. To achieve this feat, they used a Monte Carlo
algorithm which generated random numbers that correspond to certain
musical features like pitch or rhythm. Using a set of restrictions,
these random features were limited to elements that would be musically
‘legal’ as defined by traditional musical theory rules, statistical
probabilities (like Markov Chains), and the imagination of the two
composers.

The First Movement of Illiac Suite. Click the image to hear the
sample.
Another innovator in this field was Iannis Xenakis, a composer and
engineer, who used stochastic probabilities to aid in his music
creation. A stochastic process is a mechanism with random probability
distributions that cannot be predicted but can be analyzed
statistically. In the early 60s, he utilized computers and the FORTRAN
language to interweave multiple probability functions to determine
overall structure and other parameters (like pitch and dynamics) of a
composition.

Iannis Xenakis - Photo from Paris Autumn Festival
Xenakis modeled his music as if he was modeling a science
experiment. Each instrument was like a molecule and would undergo its
own stochastic, random process to determine its behavior (the frequency
of pitch and velocity of certain notes).
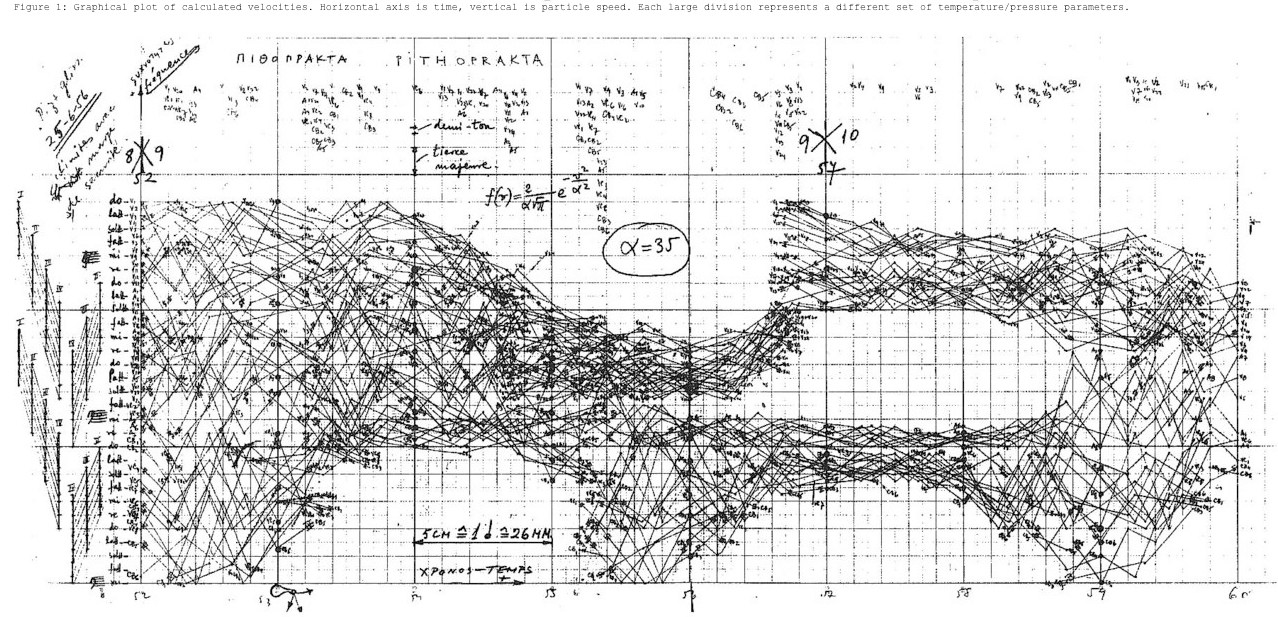
A mathematical representation of Pithoprakta, an early work by Xenakis. He models different sound spaces though these Glissandi (the glide from one pitch to another) as graphs of straight lines (time on the horizontal axis, pitch on the vertical), where different slopes correspond to different “sound spaces.” Image by Iannis Xenakis.
His work introduced new methods for sound creation, but also served as an early example of AI working as a supplementary analysis tool rather than just a compositional tool. The way Xenakis created his melodies and orchestration for different instruments drew inspiration from the sounds spaces modeled by the stochastic process.
Xenakis’s experimental piece, Pithoprakta with a graphical score.
Click the image to listen.
This duality of AI as
autonomous creators and as supplementary guides continues today as we
can see intelligent sound systems that are specialized to generate
original pieces like the Illiac Suite or to break down the science of
the sound like Xenakis’s stochastic processes.
Transitional Period — Generative Modeling (1980s - 1990s)
In the decades leading up to the modern era of music, the focus moved from simpler, algorithmic generation to generative modeling. Otto Laske, a prominent researcher in the field of Sonology, describes this change as the difference between a musical robot and musical intelligence.
A musical robot is more akin to the early experiments in the 50s and 60s — it can recognize patterns, has a grammar for music, and has a general sense of problem-solving, but it achieves its goals with fairly direct and blunt methods. On the other hand, musical intelligence replaces the robot’s brute-force searching approach with a knowledge-based understanding system with its own awareness of how musical elements may function.

Image by Franck V. on Unsplash
This trend towards AI systems building their own self-sufficient understanding of musical elements was the basis for the higher-level music intelligence we see today.
In the 1980s, David Cope (a composer and professor of music) with his Experiments in Music Intelligence (EMI) was a major believer that the scope of computer composition could include a deeper understanding of music through his 3 basic methods:
- (1) deconstruction (analysis and separation into parts)
- (2) signatures (commonalities — retaining that which signifies style)
- (3) compatibility (recombinancy — recombining musical elements into new works)
His work revolved around this idea of recombinancy where elements from previous works are combined and modified to create new pieces of music. Some of the greatest composers of all time played with recombinancy (either consciously or unconsciously) as they reshaped existing ideas/styles into their own work. In EMI, David Cope wanted to replicate this behavior through the use of computers and their computational ability.
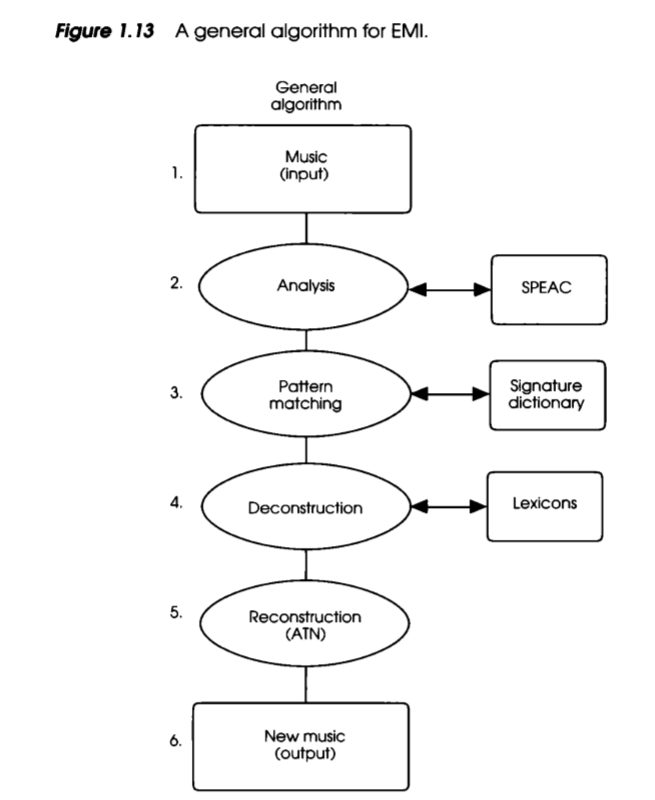
Cope’s Six-Step Process for EMI. Image by David Cope from Experiments in Music Intelligence.
Cope’s work was the foundation for many current AI models on the market right now. First music and its attributes are encoded into databases, then the collection of the recombinant segments is extracted using certain identifiers and pattern matching systems. From there, musical segments are categorized and reconstructed in a logical, musical order using augmented transition networks until new music output is produced. This type of ‘regenerative’ construction of music is reminiscent of many of the current neural networks that compose music today.

Emmy Vivaldi, A composition created by Cope’s Experiments
in Music Intelligence program. Click the image to listen.

Robert Rowe’s book explores technology in the process of music analysis, composition, and performance.
Other developments in this period continued to explore the boundaries of
computational creativity. For example, Robert Rowe created a system
where a machine can infer meter, tempo, and note lengths while someone
is playing freely on a keyboard. Also in 1995, Imagination Engines’
trained a neural network with popular melodies by triggering
reinforcement learning leading to the generation of over 10,000 new
musical choruses. Reinforcement learning involves training a neural
network to achieve a goal by rewarding/punishing the model based on the
decisions it makes reach a specified goal.
For more information about Reinforcement Learning:
https://deepsense.ai/what-is-reinforcement-learning-the-complete-guide/
For more information about Imagination Engines Neural Network:
http://imagination-engines.com/iei_ie.php
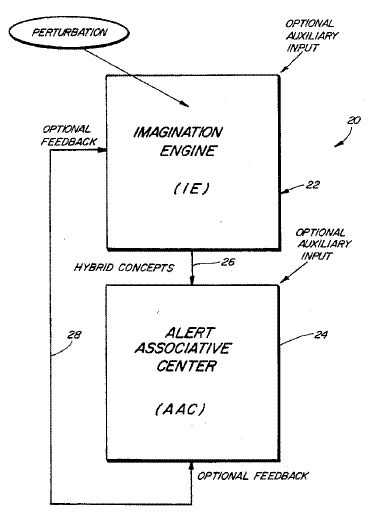
The basic outline for IE’s neural networks. Image by Imagination Engines.
Current Period (2000s - Present)
In the current era of music AI technology, the roots of generative modeling and algorithmic composition have dynamically spread into higher-level research and even into the music industry. With the use of more experimental algorithms and deeper neural networks, the role of AI music intelligence in the creative process has grown significantly.
Intelligent Composition with Iamus
In 2010, Melomics’ Iamus project was the first computer to compose classical music in its own style. Iamus is a computer cluster that utilizes evolutionary algorithms to compose its musical fragments, showing some divergence from Cope’s generative modeling based upon previous music.

The Iamus Computer Cluster. Photo from Materia
Like the process of natural selection, a randomly generated piece of music is mutated (changed pitch, dynamics, etc) and analyzed by a set of rules to see if it follows established rules by music theory or the genre. Eventually, this evolution allows a random input fragment to develop into hundreds of compositions that follow real music criteria after only a couple of minutes.

One of Iamus’s original compositions performed by the Málaga
Philharmonic Orchestra. Click the image to listen.
Music Analysis with Magenta
Magenta is a project started by Google Brain which uses machine learning as a tool to enhance the creative process. They have created a number of applications that display some of the capabilities of music intelligence such as transcribing audio using neural networks or blending musical scores with what are called latent space models. However, we can see the depth of Magenta’s music analysis through their experiments with MusicVAE.
MusicVAE is a machine learning model that can blend together musical scores to compose new pieces. They achieve this through the use of a latent space model, which is where higher-dimensional dataset variation is transcribed into a more understandable mathematical language. This is achieved by the use of an autoencoder which uses a dataset of melodies and compresses (encodes) each example into a vector representation, then reshapes this vector into the same melody (decoding).
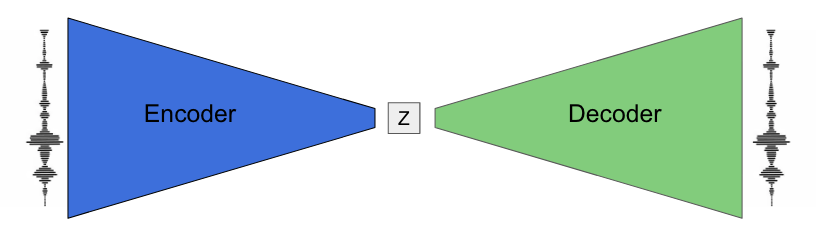
Magenta’s autoencoder compressing and decoding audio. Image by Magneta
After learning how to compress and decompress multiple inputs, the autoencoder learns the qualities that are similar throughout the whole dataset. MusicVAE is founded on this principle but adds hierarchical structures to the process to produce a long-term structure.
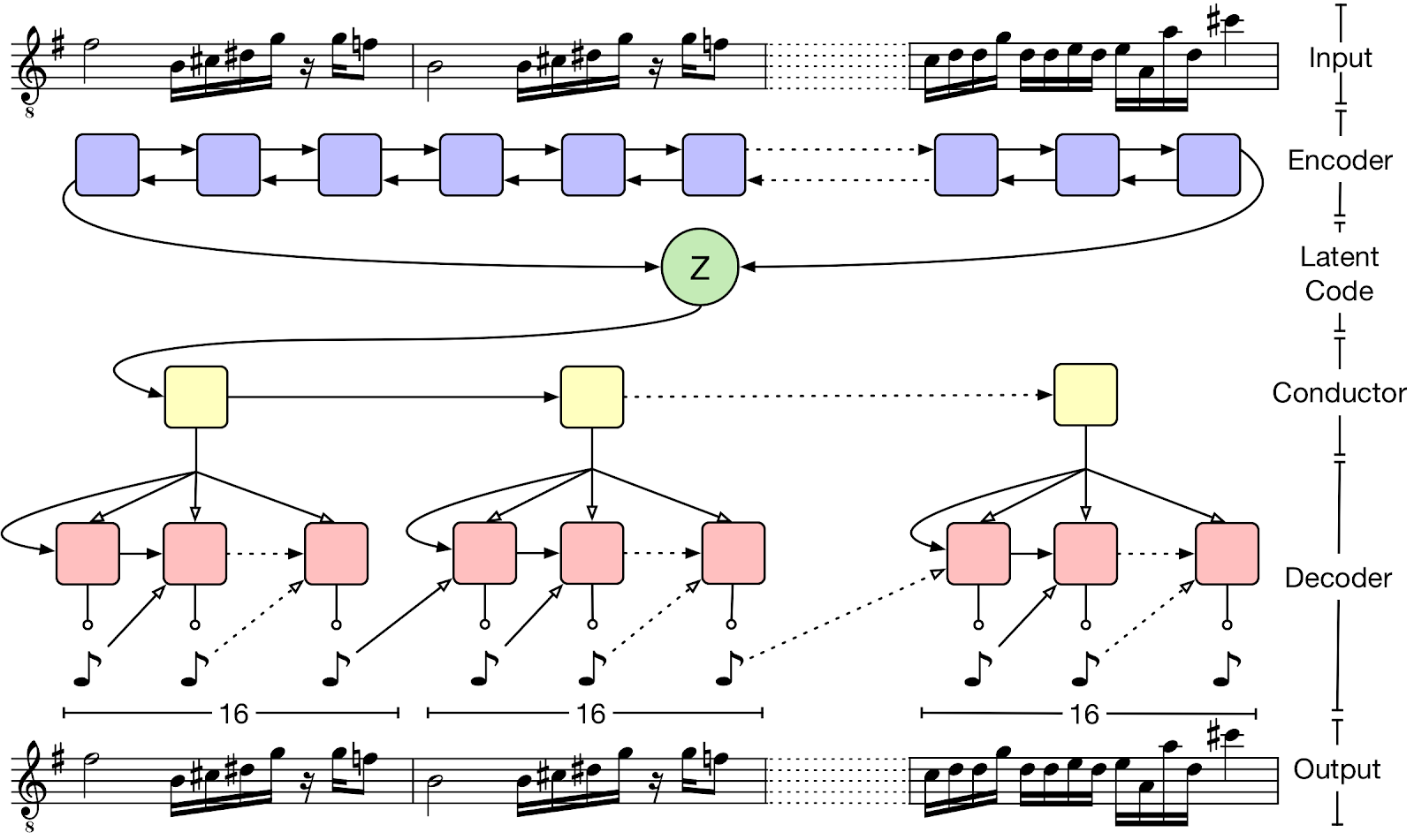
The hierarchal autoencoder structure. Image by Magneta
From this framework, MusicVAE is able to construct multiple applications for making interpolations, drum patterns, and entirely new melodic loops based on an input of your music.
Magneta creating interpolations based on two input melodies. Click
the image to listen.
Sound Synthesis with NSynth
While most early research focuses on the act of composition, current research has expanded to include machine learning in the realm of sound synthesis. Magenta’s NSynth (Neural Synthesizer) utilizes neural networks to make sounds at the level of individual samples rather than from oscillators/wavetables like traditional synthesizers. This approach allows for more artistic control over timbre (the distinct character of a sound) to further assist in the creative process.

Hector Plimmer experimenting with the NSynth Super instrument. Click
the image to listen.
NSynth uses what is known as a Wave-Net style autoencoder on a dataset of 300,000 musical notes from roughly 1,000 instruments. This unique dataset allows for the factorization of a musical sound into notes and other qualities based on this relationship based on the total probability theorem.
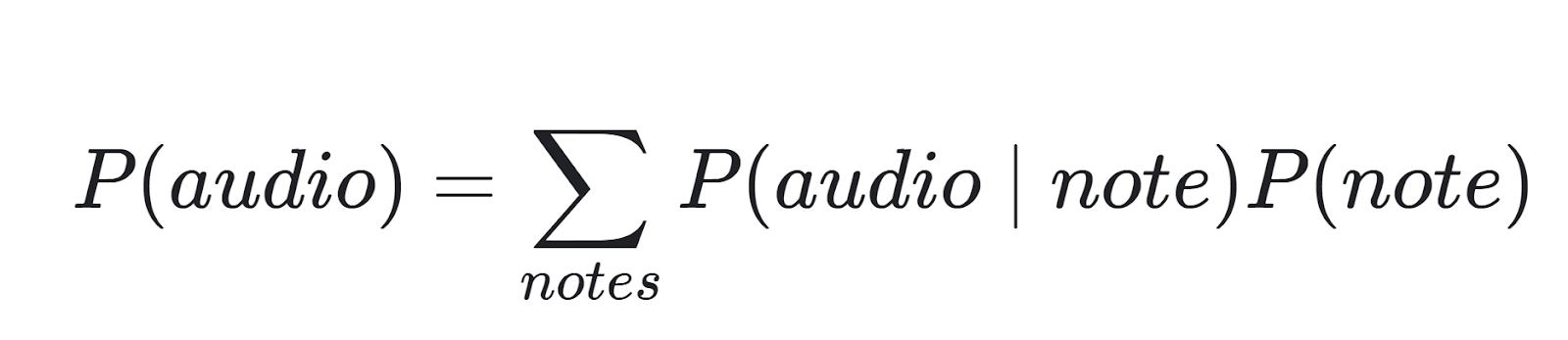
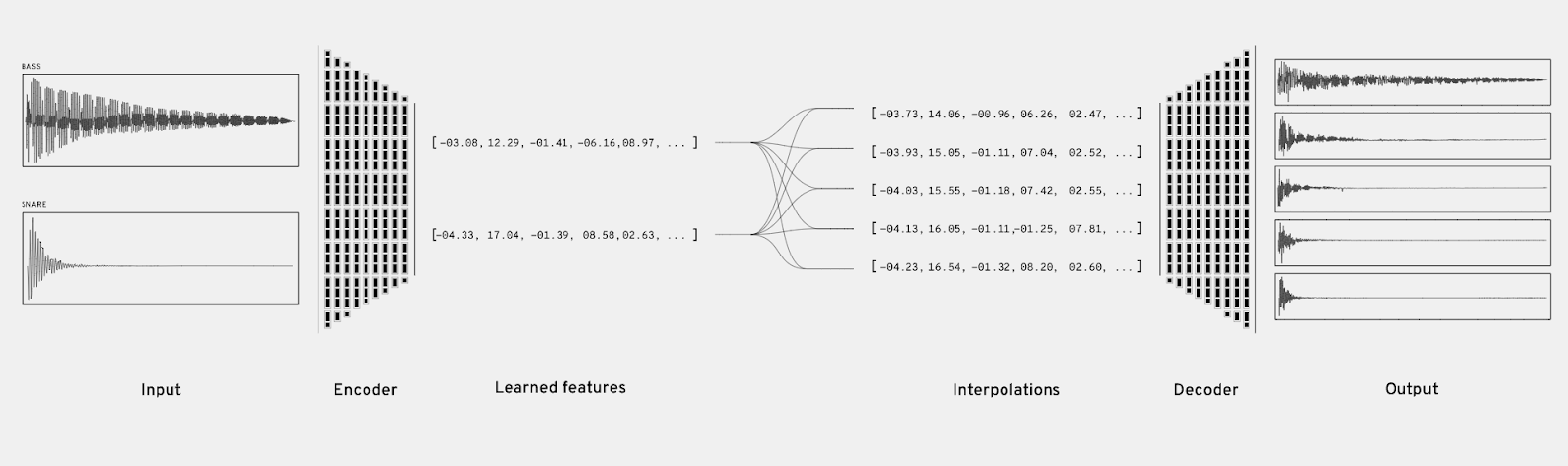
NSynth’s encoding process can create multiple sounds from two inputs. Image by Magneta
The goal of the autoencoder is to model the timbre (P(audio | note) in the equation) of a sound into latent space. NSynth employs a temporal encoder with mathematical algorithms known as convolutions. After 30 layers of these convolutions, two audio inputs are compressed into 16 dimensions corresponding to 16 temporal features of the sound. Next, this compressed data is upsampled and interpolated to make new embeddings (mathematical representations of the sound). The final step synthesizes a wealth of new sounds that hold qualities from both inputs by decoding these embeddings.
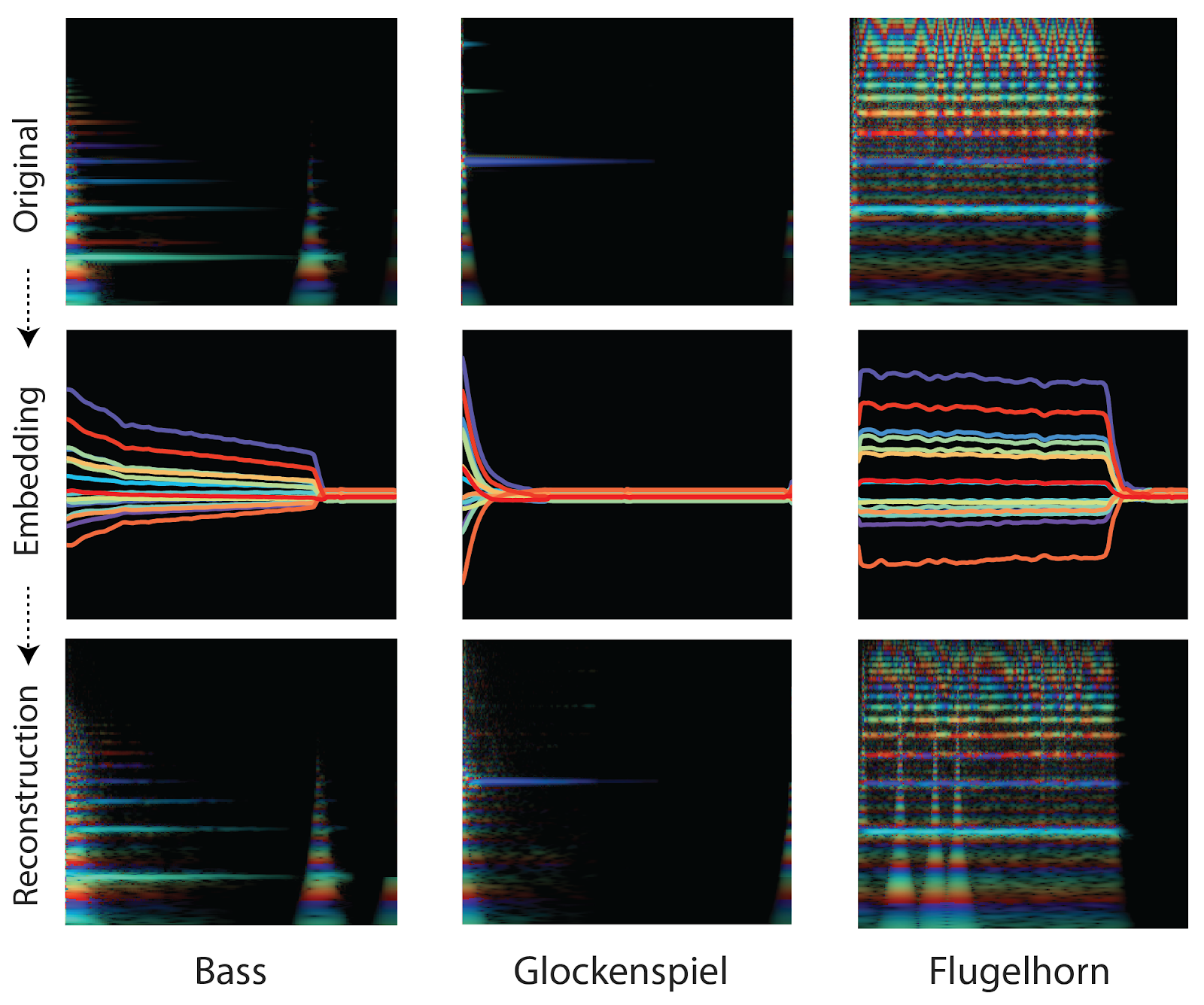
These spectrograms show the process of the audio reconstructions with the frequency of sound (y-axis) and time (x-axis). Image by Magenta.
Generative Modeling with Jukebox
Most attempts at autonomous music generation tend to generate music symbolically, usually through a piano roll or MIDI which serve as types of language that can describe sounds/sequences. OpenAI’s Jukebox takes generative modeling to a higher level by modeling music and the human voice directly as raw audio. With their approach, Jukebox can generate melody, compositions, timbre, and even rudimentary singing in a variety of genres and styles. To tackle the depth of the semantic information of raw audio, they use specialized encoders and neural networks.

Image by OpenAI
Jukebox compresses their audio into a latent space using something known as VQ-VAE encoders. The overall system starts with using convolutional neural networks to encode the audio and then finding patterns from these encodings. A convolutional neural network (CNN) is an algorithm that can take an input image and mathematically represent its unique features through matrices of multiple dimensions. CNNs can be used on audio by applying them to a visual representation of an audio sample (such as a spectrogram). Follow this link for a more in-depth explanation of CNNs: https://pathmind.com/wiki/convolutional-network#work
To combat loss of musical data in this encoding process, Jukebox also employs a combination of loss functions and upsamplers to retain information. These patterns are then decoded into a novel audio using more CNNs.
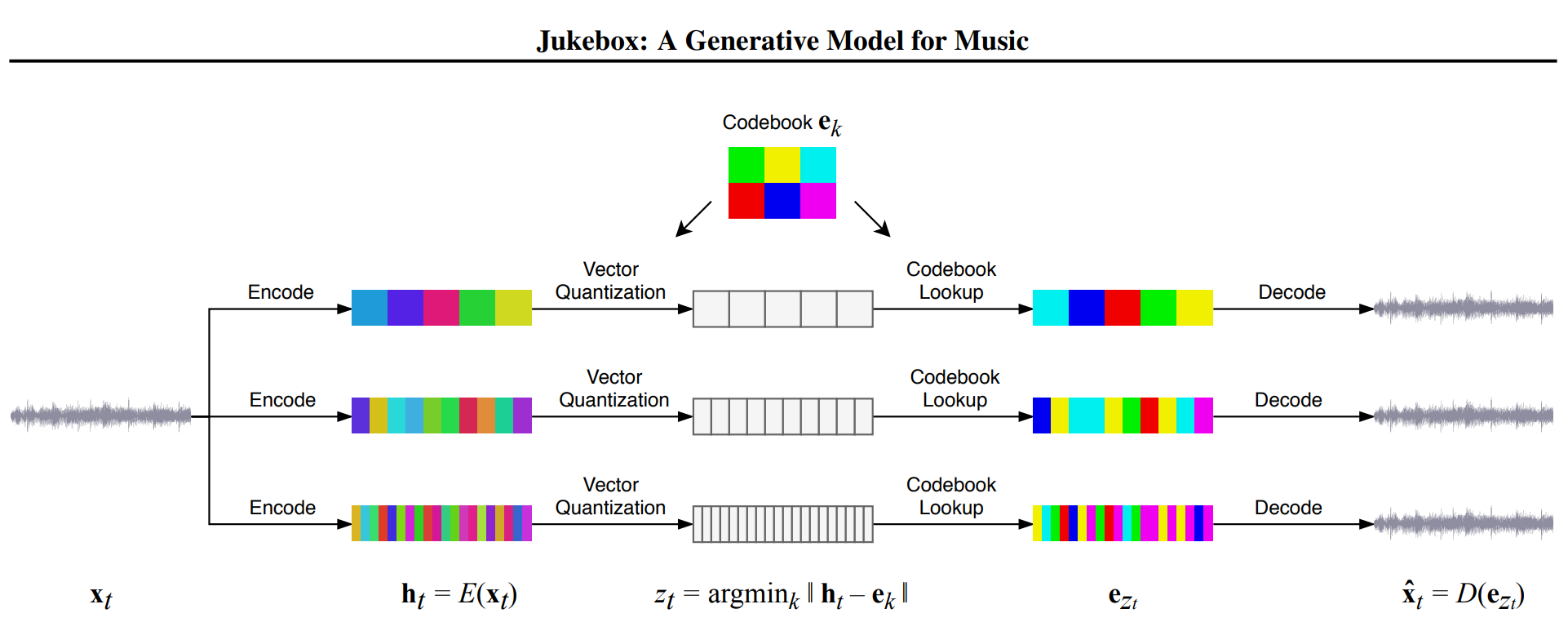
3 separate VQ-VAE models at different temporal resolution. Image by OpenAI
However, Jukebox differs from other models with the nature of VQ-VAE as it is essentially an autoencoder with a something called a ‘discretization bottleneck’ which means that it retains different amounts of musical information at three independent reconstruction levels (each level encodes a different amount of information). This use of separate encoders, rather than a hierarchical system allows their model to better handle the raw audio latent space as audio can be reconstructed from any of the three layers.
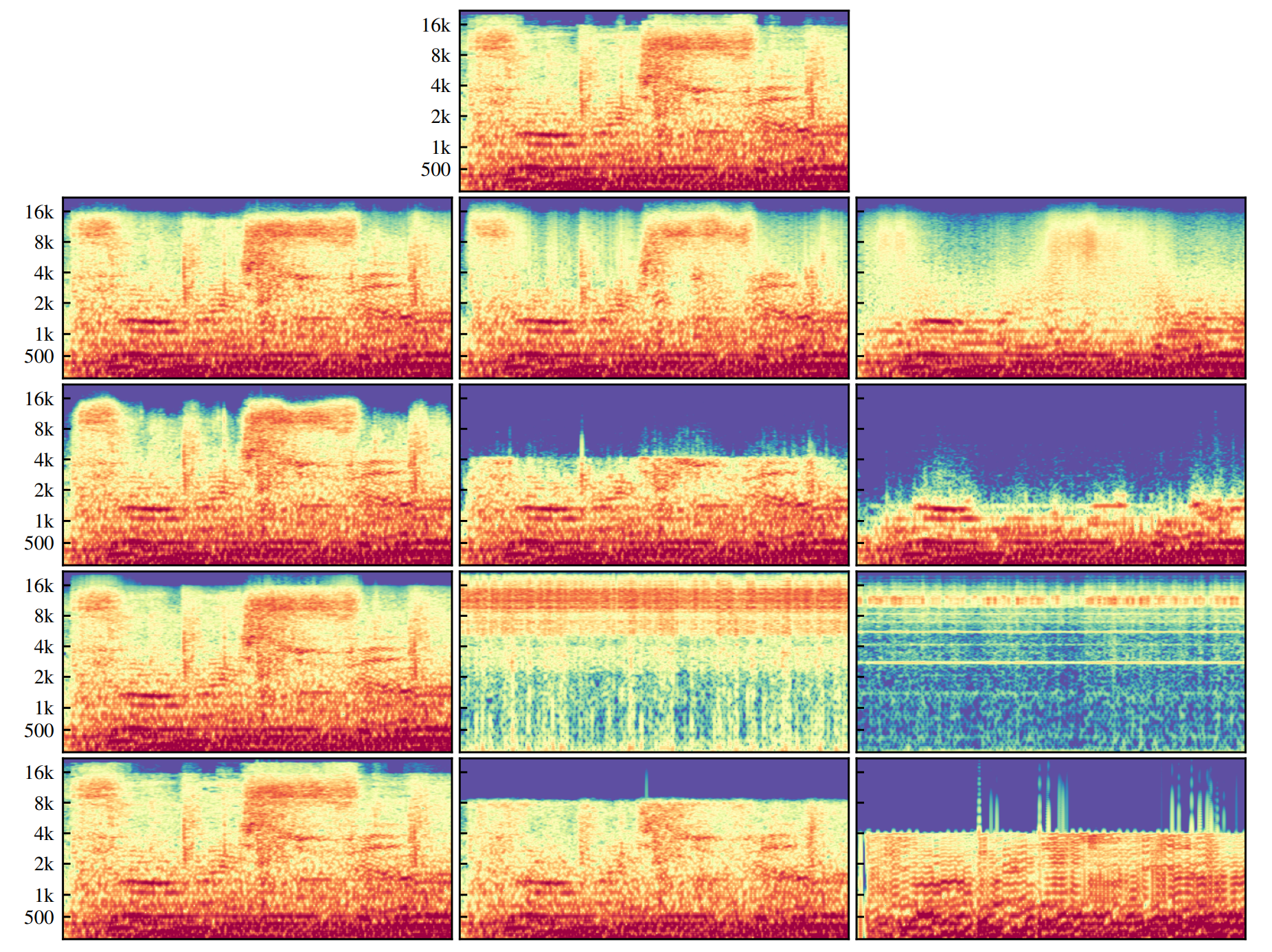
Spectral Reconstruction comparison of different VQ-VAEs with x-axis as time and y-axis as frequency. The three columns are different tiers of reconstruction. Top Layers is the actual sound input. Second Row is Jukebox’s method of separate autoencoders. Third row is without the spectral loss function. Fourth row is a hierarchical VQ-VAE. Fifth row is a similar Opus codec encoder. Image by OpenAI
After learning from a dataset of 1.2 million songs, Jukebox shows a step forward in generative modeling of music through the use of audio. With musical coherence, traditional song patterns, solo performances, and the replication of the human voice appearing in the generated songs, we can clearly see the progress from early ideas of recombinancy or algorithmic composition.
Trained on the first 12 seconds of audio, Jukebox recreates the rest of this Bruno Mars song in its own way.
Elvis Presley singing lyrics generated by OpenAI’s researchers and language model.
Lil Nas X’s Old Town Road performed by Alan Jackson as a Country song.
Other Breakthroughs
The continual growth of music intelligence has led to this technology moving into numerous more commercial applications. For instance, LANDR utilizes deep learning algorithms for automated audio mastering. Additionally, many products have utilized combinations of neural networks and reinforcement learning algorithms to release commercial songs such as an album by Taryn Southern (co-produced by Amper Music) and the Hello World album (made with Sony’s Flow Machines with artists). As these algorithms and neural networks grow, we will see more AI-assisted music in mainstream settings in the near future.
Image by Trevor Paglen
As AI technology has become more refined from the pioneering ideas of researchers like Hiller/Isaacson and Cope, its prevalence in the music industry has exponentially grown. Commercial applications are assisting artists in their creative process or even for soundtracks and background music, yet the role of the human mind in the artistic process is still necessary for the true emotional and creative depth of original music.
As the accessibility and capabilities of AI technology grow, they will undoubtedly change the music industry. However, instead of surrendering to this inevitable change, musicians can learn and adapt their creative processes to use AI music intelligence as another step in the evolution of their creative arts.