Journey to GPT2
Nicholas Deas, July 10, 2020
“Artificial Intelligence is, in essence, a software. We might not be able to do much about it as a computer science, but we can make a few things about it.”
This quote was written by a generative language model called GPT-2, a special type of machine learning model designed to create text mimicking natural language. While not exactly correct, the quote does make grammatical and thematic sense. This is typical of generative language models, but the machine learning community has continually developed new and improved models to achieve greater coherence. In this post, we will walk through the developments in machine learning that led the community to GPT-2, beginning with Recurrent Neural Networks and ending with GPT2 (demo of GPT2 can be found here).
Recurrent Methods
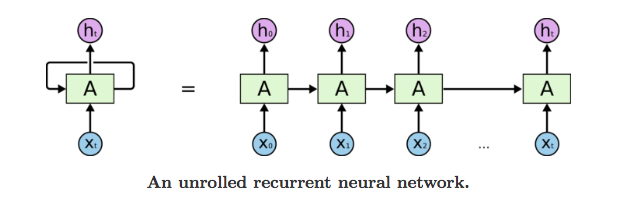
Feed-forward neural networks are one of the more basic forms of neural networks, involving the processing of inputs only in one direction, from input to output. However, recurrent neural networks (RNN) process data in loops, with outputs of a layer being reused as part of the input in the next time step. This gives the architecture a method of remembering previous inputs, also allowing it to perform tasks like generating language. So, in attempting generation, an RNN uses its previous input or a seeded input to predict the next word in the sentence one at a time, feeding the new prediction of the previous timestep in as a new input.
However, this architecture has a few problems. Though RNNs may be able to handle short sentences, they struggle to capture relationships in the text separated by more than a few words. This performance issue arises because the RNN has no mechanism for holding onto important information for many time steps. As the recurrence continues, the information from the beginning of the task is quickly replaced by the numerous inputs in the sequence, limiting the network’s ability to capture subtle meaning in the text. For example, if an RNN were to process the sentence:
“John loves reading articles on natural language processing, language generation, and especially his favorite article about how attention works in machine learning models, but soon he hopes to write one of his own,”
it may fail near the end of the sentence to infer that he refers to John, as the two words are so distant from each other in the input sequence. This problem of information loss in earlier time steps is known as the vanishing gradient problem. There is a small chance that the opposite can occur, where the model becomes unstable with extremely large weights that grow exponentially, and this is called the exploding gradient problem. At the same time, this looping behavior that allows RNN’s to incorporate recent time step information, also prevents the model architecture from being easily parallelized, as no time step can be completed before the preceding timestep.
Long Short-Term Memory
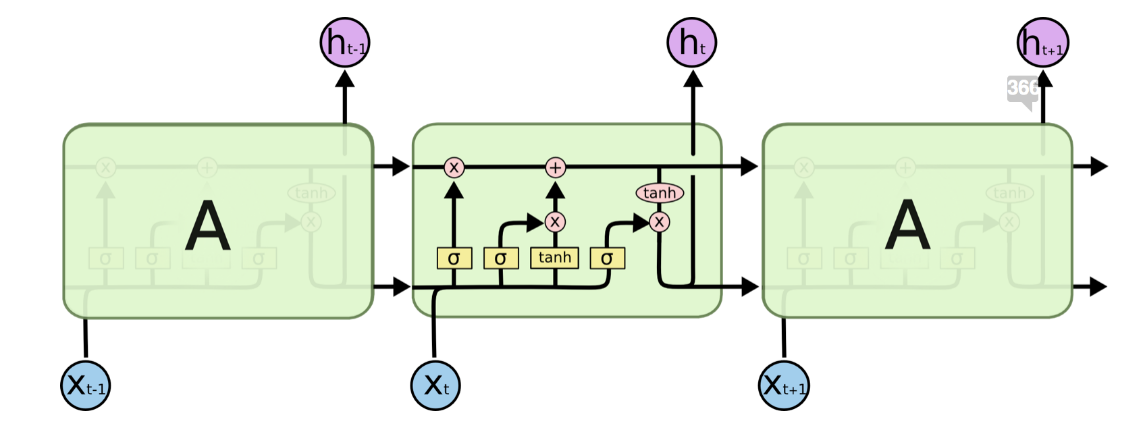
To resolve some of these RNN issues, a new architecture was designed to better handle long-term relationships in text. This Long Short-Term Memory Network (LSTM), is a variation on the normal recurrent network, with similar looping behavior. To account for the former’s weaknesses, the LSTM incorporates gates in its layers that allow it to filter out memories that should be forgotten, and overall regulate the addition of new memories. These gates in addition to this additional memory allow for longer topical relationships in generating language, an advantage over normal RNN’s, and as a result, the LSTM was the state of the art model in the late 2000’s.
So, why not use LSTM’s? While resolving some inadequacies of the RNN, LSTM’s still create problems as well. With these added gates also comes added complexity and needed processing power, leading to slow training and task completion time. Similar to RNN’s, these models also cannot be easily parallelized because of their recurrent nature, adding to the arduous training and task completion times. The added processing also makes the architecture extremely vulnerable to overfitting, even with added contingencies such as Dropout layers, and the result of training is very sensitive to initial values for weights. Most importantly, LSTM’s still struggle to represent long term dependencies, although it is more capable than RNN’s. Storing information in these memory cells does extend the length of stable dependencies, but LSTM’s face the same problems as RNN’s in long passages.
Attention
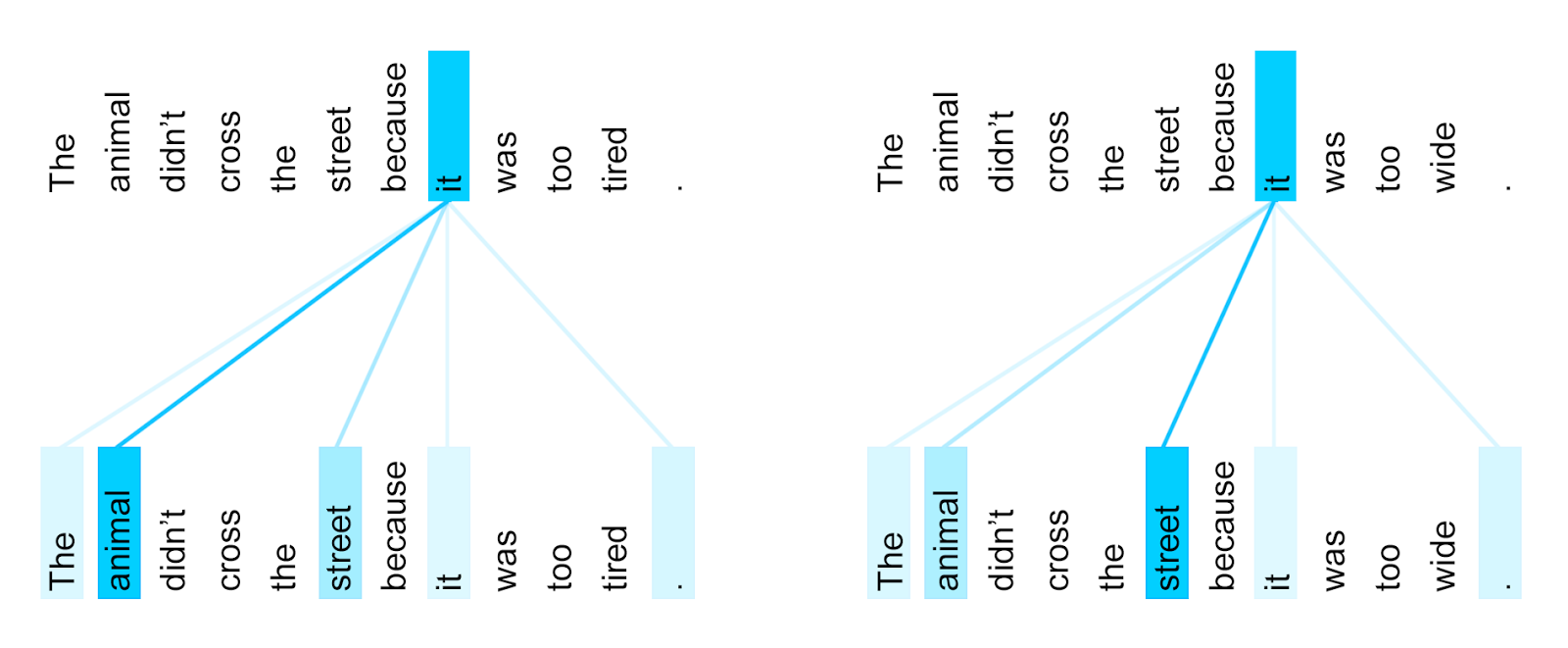
While these recurrent models were the standard for language processing and generation, a new method quickly became superior. This concept that led to a new generation of natural language models was called Attention. Attention can be interpreted literally: an Attention module takes in input sequences and constantly evaluates which tokens are most important for the task. This mechanism acts similarly to how while reading this, you most likely disregard words that serve a more grammatical purpose like articles (“the”, “a”, “an”), but pay special importance to keywords like proper nouns and verbs. In its most basic form, Attention involves taking two separate sequences, like two consecutive sentences, and assigning importance to relationships between all combinations of words in the first and second sentence. This is how Attention is able to better handle long-term.
An important variation of Attention – Self Attention – uses the same method as above, but instead compares a sentence to itself in assigning importance to word dependencies. As well as taking in long-term dependencies into account, an Attention module can also give value to shorter-term dependencies at the sentence level. The combination of these two abilities sets the stage for new attentive models that offer greater capabilities over the previous recurrent models.
The Transformer
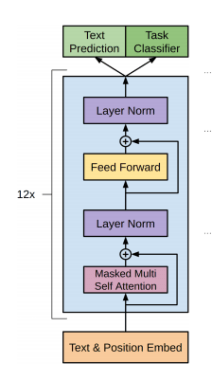
The concept of Attention enables the creation of stackable and parallelizable module for natural language processing–the Transformer. Different configurations of these modules allow for the creation of impressive models like GPT-2 and its peers.
The Transformer architecture, although arguably as complex as LSTM’s when considering the processing needed for Attention, is much less demanding of computing resources, and also allows for parallelizing the model, as the different parts of the transformers can be executed simultaneously. Primarily, the space required is drastically lessened with the use of the Attention mechanism to incorporate important long-term memories without incorporating a running memory or hidden state. At the same time, the Attention mechanism outperforms the capabilities of the LSTM when used correctly or in abundance, creating a platform for a better generation of language models.
GPT-2
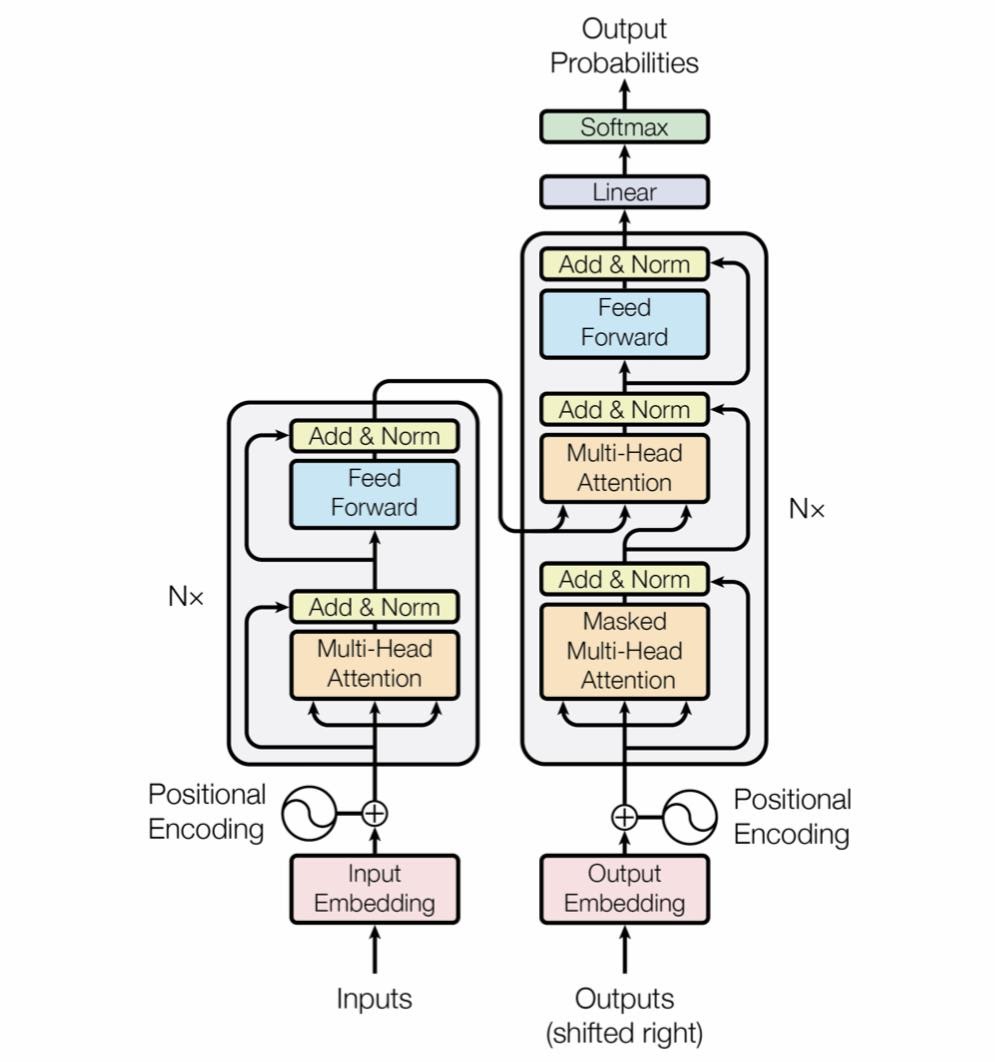
Finally, we have GPT-2, one of the many state-of-the-art models that has come out of the Transformer architecture. Many different models were built on this concept for different language tasks with different alterations. One example, BERT, uses stacked Transformer encoder units for deep natural language understanding, allowing it to perform classification and encoding tasks with great performance. However, BERT is unable to perform language generation because of its architecture. Its method of training only allows it to predict randomly positioned words in a sentence, making it inefficient for language generation.
Contrarily, GPT-2 is built using modified Transformer modules. These are stacked so that the output of the last serves as the input to the next. And, because these models are made of independent modules, we can also create bigger and potentially more powerful models by adding more modules! The different sizes of GPT-2 models offered–Small (124M Parameters), Medium (355M), Large (774M), and X-Large (1.5B)– are simply different numbers of these stacked modules, leading to more predictive power (as well as more potential for overfitting), with more layers. The generated language outputs of even the smallest GPT-2 model can be eerily accurate, and you can interact with this model trained on different specialized data sets below.
Demo
Here is an interactive demo to view GPT-2 generated passages on your own. The demo was created using the Github Repositories gpt-2-simple and gpt-2-cloud-run[link to repos], and all models endpoints are hosted through IBM Cloud. Below, you will find some generated passages trained on different datasets that exemplify the performance of GPT-2. All of the model outputs use a small phrase or seed, indicated in bold, input by the user as a basis for the rest of the generated text.
GPT-2 Base Model (Small)
GPT-2 Models are a good starting point for developers looking to take a look at the various models of the C++ language. The C++ model comes with many features, but the most interesting feature is that it allows you to create your own C++ code. There are many different types of C++ code that are available to you, and it will probably take more time to write your own C++ code.
Passages generated by even the small, base model for GPT-2 are coherent and passably human. Issues tend to lie at the comprehension level, such as in the second sentence, as sound logic usually involves contextual knowledge of the passage subject matter, and generative models are not trained to incorporate this knowledge. The model specifications used were given directly by OpenAI, the creators of the GPT-2 architecture, so there is no fine-tuning involved to focus the model’s output on any specific areas or training data.
Trump Tweets
‘America needs to be smart, tough and vigilant in handling terrorism.’ ‘Hillary Clinton is part of the problem today, not a solution tomorrow. We need smart, tough and vigilant people handling terrorism!’ ‘RT @gatewaypundit: INTERVIEW:@realDonaldTrump takes a breath, looks directly into camera, and then returns 20 seconds later, FULL SWING, LIES https://t.co/H9OZ9Lbq8k #VPDebate #POTUS’
Exemplifying the ability to customize GPT-2 behavior based on training data are those models that are fine-tuned for tweet text. The above generated passage’s model was fine-tuned on President Trump’s tweets based on the GPT-2 Small model, and this is evident in the details of the text. Despite a vague seed, the model generated output that focused on other political figures (“Hillary Clinton”), mentioned Trump’s Twitter handle, and mimics how he writes on Twitter. The model was even able to learn the normal length of a Tweet and signal the division between tweets with apostrophes, as done in the training dataset.
Song Lyrics
I feel like a dog. Oh, I feel like a dog. Oh, I feel like a dog. I feel like a dog. I feel like a dog…
Despite many successful results, GPT-2 models do still have limitations and like most machine learning models, performance heavily depends on the dataset. When fine-tuned on song lyrics, GPT-2 models generate passages like the example above. While real songs don’t usually have this much repetition, the model learned this pattern or repeated phrases. This phenomenon can be partially resolved by changing the temperature of the language generation – a parameter that allows less likely words to be selected: I feel like I never had anything worth doing. I feel so far away now and I can’t feel the way I do. I feel like I never had anything worth doing. (I feel so far away now and I can’t feel the way I do)
Natural Language Generation has experienced large advancements in recent developments such as GPT-2 and it’s contemporaries. While not perfect, it shows how well current models are able to understand language with applications in language translation, chat bots, and automated custom content creation. The GPT-2 Small model itself summarizes Natural Language Generation well: “Natural Language Generation is an approach to solving problems. It is a way to produce a language that is more expressive, more powerful and more efficient.””