Improving Qualitative Analysis with Triplet Labeling
Quinn Hubbarth, December 16, 2020
Qualitative analysis is a useful method to find themes in many different forms of data, and traditional methods of research can be significantly improved with machine learning. Qualitative research with machine learning is a difficult challenge, and a large problem associated with qualitative research is labeling data. Because qualitative data is hard to generate on a large scale, it often requires a lot of effort from researchers to label the data for analysis.
For a little over a year, our research team has focused on creating a machine learning method for qualitative research that alleviates this burden on the researchers. This semester, we’ve tried to help researchers by developing a method that doesn’t require researchers to have a fixed set of labels before doing analysis. This allows researchers to focus on the ideas they’re trying to explore rather than having a set of codes to adhere to. One method we thought would solve this problem was triplet-constrained representation learning. In this method, researchers look at 3 different datapoints, a, b, and c. The researcher then must determine if datapoint a is more similar to b than c according to some high-level criteria that the researcher defines in advance. This is a simple way for the researcher to label data quickly, because the researcher only needs to provide a “true” or “false” label and the triplet formulation resolves a lot of the ambiguity present when evaluating similarity between only two examples. This also fixes issues with the data understanding because the researchers no longer need to try to find important relationships in the data beforehand, as researchers can determine relationships while labeling the data. The example below shows how this works for labeling triplets of hand-written digits where two images are considered similar if they represent the same digit:

Figure 1
This article will outline the work we’ve done this semester to implement this new method, as well as the next steps we need to take to improve it. So far, we’ve tested the method on the popular MNIST dataset of hand-written digits (see figure below), and we’ve gotten some promising results. However, more improvements need to be made to reduce the required number of labeled triplets, and this article will detail some of the improvements we’ve been working on.

Figure 2
Simulating with MNIST
In order to make sure that the triplet labeling method is effective for machine learning, we wanted to test it on a relatively simple dataset: MNIST hand-drawn digits. We developed, trained, and tested a neural network model that learned to classify MNIST images to test the triplet method.
How does the neural network train on these images?
In order to use MNIST images in a triplet-based neural network model, we needed to create a dataset that has random triplets of images for our model to receive and evaluate (see figure 2). This allows the neural network to receive triplets as datapoints, evaluate whether image a is more similar to image b than image c, and train the model to predict this. To train the model, the neural network first encodes each image in the triplet as a sequence of numbers. Then, the model computes a distance between images a and b and images a and c. Finally, the model uses these distances to make a prediction about whether a is more similar to b than c (see figure 3). Based on whether the prediction is correct or incorrect, the model will update to become more accurate.
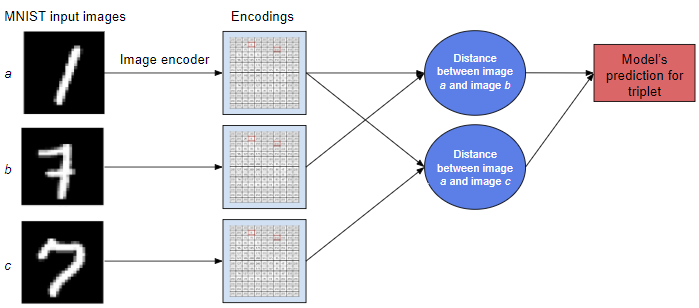
Figure 3
How do we determine whether two images are similar or dissimilar?
But what does it mean for MNIST images to be similar? We use several different criteria to evaluate similarity between MNIST datapoints. These criteria look at the true value of the digit and return true or false based on some numerical criteria, including primacy, parity, or numerical closeness. If the criteria evaluates MNIST datapoints based on primacy, the criteria function will return true if a is prime, b is prime, and c is not prime (or vice versa) and false otherwise. For example, in figure 1, both triplets would evaluate to true, because both 1 and 7 are prime numbers. These criteria will eventually train the model to separate prime numbers from not prime numbers. We programmed many different criteria functions that can successfully separate these datapoints into different groups.
Figure 4
Although these results are quite promising, MNIST is a relatively simple dataset, and our model must train on many samples before it converges to produce results. In order for triplet-based learning to be effective for qualitative research, we will need to improve our model to reduce the number of samples our researchers have to label. If researchers have to label thousands of triplets, it won’t be a very effective way to do qualitative research.
Improvements, Next Steps, and Conclusions
There are many methods we could use to improve our triplet model (such as tuning hyperparameters or network architecture), but we thought some of the best methods we could use would be pretraining and active learning. Both of these methods should reduce the amount of samples the researchers need to label, and make the model more accurate. Pretraining the encoder and the distance function would help the model learn from fewer samples by giving the model a good baseline before actually incorporating feedback. Active learning would ensure that the model learns efficiently because it incrementally queries the researcher to label datapoints that the model is most uncertain about. Using pretraining and active learning, we eventually hope to achieve a process similar to the flowchart depicted in the figure below.
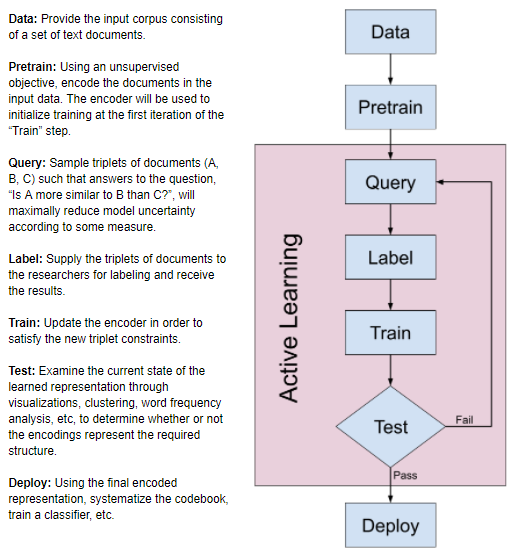
Figure 5
Next semester, we hope to use these improvements to build on the MNIST model and eventually move to qualitative analysis of text data. Unlabeled text data has been difficult for us to work with so far, but we hope that this triplet method (with improvements) can be useful for qualitative analysis. It’s possible that text data will introduce new challenges that the MNIST test didn’t have, but if this method is effective, it will be very helpful for our researchers in performing large-scale analysis of qualitative text data. We are hopeful that labeling triplets will be far more simple than other methods of labeling text data and will help us create a great tool for qualitative researchers.